Spec-Kit 使用
安装
官网:https://github.com/github/spec-kit
## 安装 CLI 命令行工具
uv tool install specify-cli --from git+https://github.com/github/spec-kit.git
## 升级 CLI 命令行工具
uv tool install specify-cli --force --from git+https://github.com/github/spec-kit.git
初始化项目
## 初始化创建新项目
specify init <PROJECT_NAME>
## 在已有项目目录中初始化
## . 或 --here:指明在当前路径操作,不创建新文件夹
## --ai claude:指定使用的 AI 助手,此处使用的 claude code
specify init . --ai claude
或
specify init --here --ai claude
## 检查运行该工具所需的软件依赖(如 Python、Git 等)是否已正确安装,确保后续 AI 代理能够正常调用相关脚本
specify check
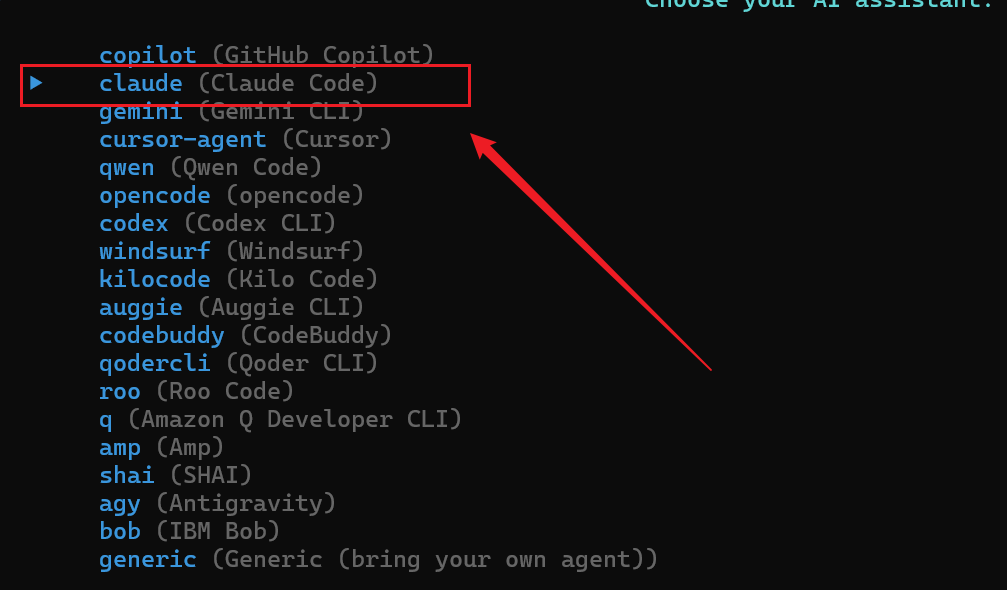
初始化 spec-kit 项目时会提示要使用 AI 工具和命令行工具;此处选择 claude code 作为 AI 助手工具,Window下选择 PowerShell 作为命令行工具,如下:
- 选择 AI 工具:
- 选择命令行工具:

基本使用
Spec Kit 将开发过程分为核心工作流和质量增强两个部分;核心工作流中是必须要执行的步骤,以便生产项目的范围说明;质量增强是可选的。
a> 在 AI 工具中执行 spec-kit 命令
在 spec-kit 项目目录中打开 AI 工具,然后就能看到 spec-kit 相关的命令,如下图:
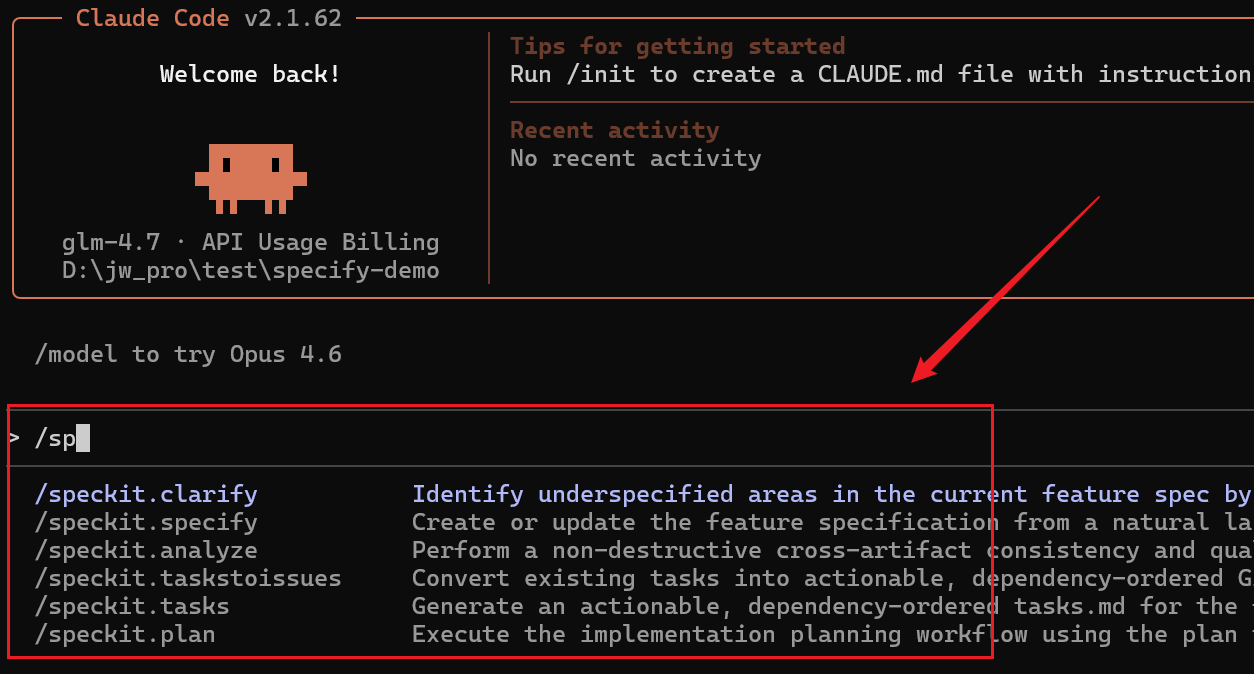
b> 依次执行如下命令,以完成核心工作流
/speckit.constitution(制定宪法,这是项目的“法律”,Claude 启动时会自动读取)
## 作用:建立项目的核心原则和开发指南(如:必须使用 TypeScript、优先考虑性能、UI 必须简洁)。
## 目的:确保 AI 在后续生成代码时,始终遵守这些“不容挑战”的底线。
/speckit.specify(定义需求)
## 作用:详细描述你想实现的功能。
## 关注点:只谈 “做什么 (What)” 和 “为什么 (Why)”,不谈具体的代码实现方案和技术栈。
/speckit.plan(制定技术计划)
## 作用:基于需求,确定 “怎么做 (How)”,使用什么技术栈和架构等;
## 内容:AI 会生成技术架构、数据库模型、API 定义等。
/speckit.tasks(拆解任务)
## 作用:AI 根据计划将庞大的计划拆解为一个个具体的、可执行的、细粒度的 待办清单(Todo List)。
/speckit.implement(执行实现)
## 作用:AI 会根据前面生成的任务清单,逐一编写并提交真实的代码。
c> 以下增强命令可选的,用于在关键节点“查漏补缺”,提升项目的严谨性:
/speckit.clarify(澄清疑问)
## 时机:在 specify(需求)之后、plan(计划)之前使用。
## 作用:AI 会化身“挑刺的产品经理”,针对你描述不清晰的地方提问,帮你规避需求模糊带来的风险。
/speckit.analyze(一致性分析)
##时机:在 tasks(任务)之后、implement(实现)之前使用。
## 作用:检查“代码任务”是否背离了最初的“项目宪法”或“需求规范”,防止开发跑偏。
/speckit.checklist(生成检查清单)
## 时机:在 plan(计划)之后使用。
## 作用:自动生成质量验收清单,用于验证需求是否完整、逻辑是否自洽。
上下文管理
由于AI 模型的上下文窗口限制,混合处理宪法、需求、计划等所有步骤,会导致性能下降和“遗忘”关键指令。SDD 类框架在处理任务时,并不依赖对话历史来记住项目规则,而是将这些信息文件化,让 AI 模型在需要时按需读取;以下是上下文管理的最佳实践:
定义宪法独立会话:确定代码风格、架构原则后写入 CLAUDE.md,完成后使用 /clear 重置上下文。
制定需求按功能划分会话:每一个独立功能(Feature)开启一个新会话;制定需求时引用宪法,生成该功能的 Spec 文件。
执行计划短期、高频重置:使用 /tasks 开始实施;每完成一个关键节点并提交代码后,重置上下文,然后通过读取 tasks.md 恢复执行进度。
最佳实践:
定期重置:完成特定任务或分支合并后,使用 /clear 命令。过长的对话历史会消耗 90% 的上下文,导致推理能力下降。
使用子代理 :使用自定义子代理;
监控用量:每 20 分钟定时检查 Token 消耗情况,避免任务执行过程中 token 耗尽导致报错;
主动总结:必要时手动压缩上下文,但这不是最佳实践,因为压缩上下文可能导致细节丢失,需求应该写入到 spec 需求文件,严禁让在没有更新 spec.md 的情况下开始执行任务 。
当 AI 模型开始出现“道歉”、重复输出代码块、或者忽略刚提的小细节时,这就是上下文污染的信号,应该立即 /clear
验证循环(Verification Loop):在 tasks.md 中,任务颗粒度要足够小,每个子任务应该是可独立验证的;最好是每个任务执行完成后执行测试,只有测试通过的代码才叫“完成”,才能记录到 tasks.md 中。不要让 AI 觉得“写完了”就是“做好了”。
CLAUDE.md 膨胀: 宪法文件如果写得太长(超过 200 行),它本身就会吃掉大量的初始上下文。保持精简,只放原则,不放具体业务逻辑。
静态宪法和动态需求:将 宪法 作为全局静态配置(CLAUDE.md),将 需求与计划 作为动态任务文档。通过 “新任务 = 新会话 + 读取旧文档” 的模式,可以确保 AI 始终拥有最清晰的推理空间。 最重要的是,上下文越乱,推理越散,因此必须确保一个上下文专注于一件事情,否则会导致模型注意力稀释。
总之,AI 模型是一个“智商极高但只有 10 分钟短期记忆”的超级专家;示例如下:

金句总结:一流的开发者在写文档,二流的开发者在改代码,三流的开发者在跟 AI 聊天; 保持文档的“重”和对话的“轻”,是规模化开发的关键。
上下文拆解流程
其它
a> 关于并发执行
目前的 spec-kit 核心版本在执行 /speckit.implement 时,默认并不会自动创建多个独立的并发 Agent。
它会在单会话、单 Agent 的模式下运行,按照 tasks.md 中定义的任务列表顺序执行。如果你的任务被标记为可并行或没有依赖关系,AI 可能会尝试在单次处理中批量输出代码,但这仍然是在同一个上下文窗口中进行的。底层 AI 工具的能力: spec-kit 本身是一个规范框架,它依赖于你使用的 AI 助手(如 Claude Code 或 Cursor)。如果底层工具(如 Claude Code)支持通过“子代理”(Subagents)来处理任务,spec-kit 会利用这种能力来减少主对话的上下文污染,但这更多是为了隔离环境而非真正的多 Agent 并发编程。但开发者们已经意识到单 Agent 执行的效率瓶颈,目前 GitHub 上有相关的提议。